
【專家專訪】從大數據解讀失智症大腦影像判讀

專訪陽明大學神經科學研究所林慶波教授
|
「老年失智症就是大腦神經退化疾病,阿茲海默氏症的病人腦內會有毒蛋白沉積,我們可以透過觀察大腦的改變來診斷,但是否能在診斷之前提前察覺,早期預測、早期發現疾病呢?因為影像技術和人工智慧的快速進展,讓這件事成為可能。」專門研究腦影像的林慶波教授滑動著腦影像圖片解說道。
|
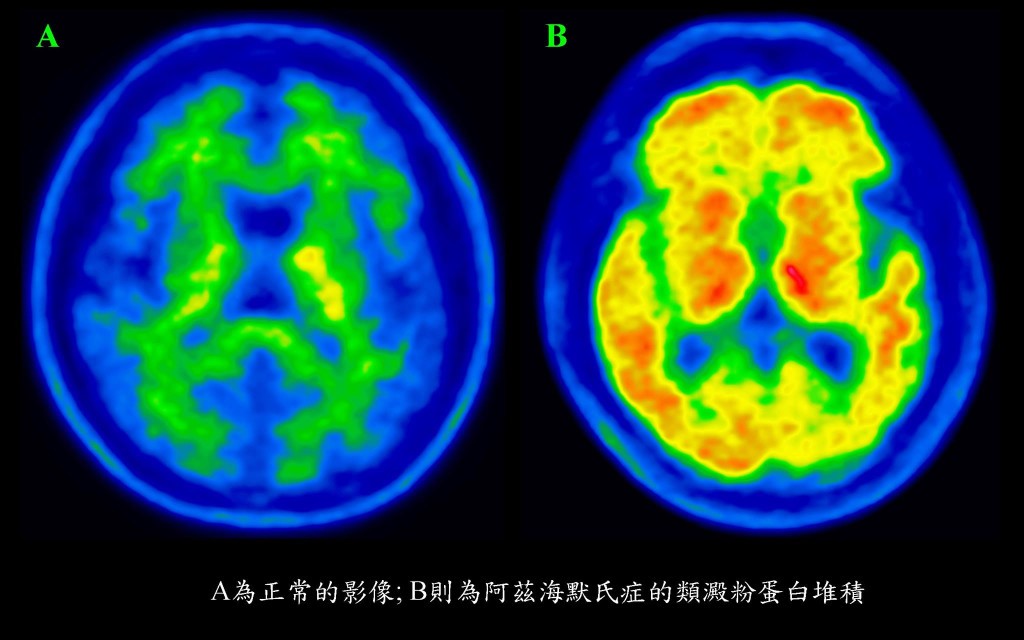
圖:正子攝影顯示,A為正常人大腦,B為阿茲海默氏症病人大腦毒蛋白沉積。
|
大數據與腦影像
現在想知道毒蛋白的沉積只能用脊隨穿刺或做正子影像,但一般人都不太喜歡,因為這些方法有侵害性,而與大腦最相關的工具就是MRI,因此研究如何利用MRI來提前觀察大腦中毒蛋白沉積是最順理成章的。
現在想知道毒蛋白的沉積只能用脊隨穿刺或做正子影像,但一般人都不太喜歡,因為這些方法有侵害性,而與大腦最相關的工具就是MRI,因此研究如何利用MRI來提前觀察大腦中毒蛋白沉積是最順理成章的。
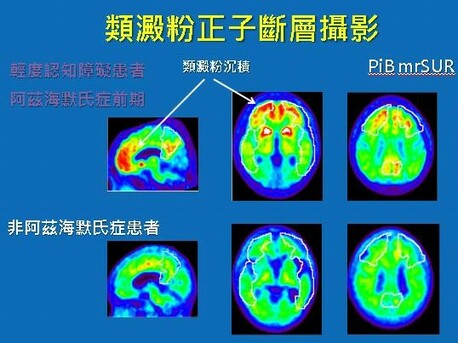
圖: 毒蛋白的沉積只能用脊隨穿刺或做正子影像探知,但一般人都不太喜歡,因為這些方法有侵害性。正子造影輻射強,使用要謹慎。
現今的MRI技術可以做到很高的解析度,可以清楚看到大腦的結構與神經的變化,大腦神經、神經連結,或是大腦的功能活動,比只能看腦活動的正子影像和對軟組織顯示並不清晰的CT理想得多,過去的研究告訴我們,罹患阿茲海默氏症時,大腦的體系會萎縮,或者活動量會改變,到了後期,病人的認知下降,同樣的透過MRI所見的腦影像,與認知相關的區塊也會變得不一樣。

圖:MRI腦影圖,(上方)阿茲海默氏病人大腦體系萎縮與(下方)正常人對照
但想要透過人工智慧分辨並統計出差異,就需要大量的樣本,不只是罹患阿茲海默氏症的病人,甚至是輕微認知缺陷的病人、一般認知表現的病人,並且做持續且長期的追蹤,但由於阿茲海默氏症不像腦中風或者腫瘤,有個異物在腦中,我們是透過一些共同的綜合特徵來診斷,比方說,罹患阿茲海默症的病人海馬迴一定會萎縮,可是海馬迴萎縮不一定是阿茲海默症病人,也有其他原因會造成海馬迴萎縮,可能是其他疾病或是正常老化,當很多共同因子混在一起,如何排除或修正就變得非常重要,這是在影像技術的提升和人工智慧的成熟後可做到的。
想要利用人工智慧分析影像技術,首先要蒐集樣本並建立數據庫,很多人誤以為收集大量的樣本,就可以提高分析的準確性,但樣本本身的可用性才是分析的關鍵。而要提高樣本的可用性,最好的方式就是長期追蹤,觀察它的改變,或者預測,但這件事情很難,因為病人沒事不會去醫院,一定是有事才去,而且我們現在也還不清楚正常人要追蹤多久才會發病,更何況MRI是很昂貴的設備,無法隨意使用,至於其他的腦影像相關的設備,在面對阿茲海默症這種沒有顯著標記、有諸多亞型的退化性疾病時,都只是提供一種機率,是否穩定或者可靠,是一大考驗。所以在想收集可用的大量樣本,執行上要付出龐大的人力與物力,到現在沒有一個比較好的數據庫可以做到。
從腦影像看失智症
與自然退化的大腦相比,阿茲海默症的病人海馬迴都萎縮了,兩者的影像差別很明顯。
想要利用人工智慧分析影像技術,首先要蒐集樣本並建立數據庫,很多人誤以為收集大量的樣本,就可以提高分析的準確性,但樣本本身的可用性才是分析的關鍵。而要提高樣本的可用性,最好的方式就是長期追蹤,觀察它的改變,或者預測,但這件事情很難,因為病人沒事不會去醫院,一定是有事才去,而且我們現在也還不清楚正常人要追蹤多久才會發病,更何況MRI是很昂貴的設備,無法隨意使用,至於其他的腦影像相關的設備,在面對阿茲海默症這種沒有顯著標記、有諸多亞型的退化性疾病時,都只是提供一種機率,是否穩定或者可靠,是一大考驗。所以在想收集可用的大量樣本,執行上要付出龐大的人力與物力,到現在沒有一個比較好的數據庫可以做到。
從腦影像看失智症
與自然退化的大腦相比,阿茲海默症的病人海馬迴都萎縮了,兩者的影像差別很明顯。
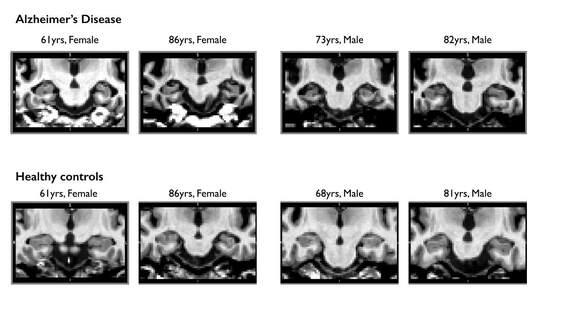
圖:上排圖為阿茲海默症病人海馬迴萎縮,下排圖為同齡層同性別健康人海馬迴對照
「可是海馬迴萎縮是阿茲海默症的特徵,但並不代表海馬迴萎縮一定是阿茲海默症,這是很重要的關鍵。」林慶波教授強調。
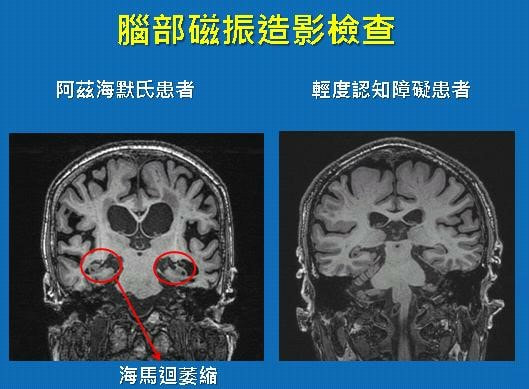
圖:MRI造影顯示阿茲海默氏患者海馬迴萎縮,須綜合判斷,區別其他疾病。
以失智症臨床診斷來說,現在知道大腦中有β-淀粉样蛋白或tau蛋白的沉積,可用正子影像與藥物做檢測,但神經影像只扮演輔助的角色,醫師會做MMSE或者一些臨床檢查,檢查完之後,再做神經影像,除非腦瘤腦、中風這種一眼就看出來的影像,否則醫生是透過很多訊息,用排除法或者共同特徵組合來下判斷,就算是MRI影像也只是一種輔助的工具,或可幫助區分不同類型的失智症。
也因此,我們還不能夠光憑著腦影像就區別一般老化或者阿茲海默症的腦,雖然可能可以透過一些相關特徵來推測,如阿茲海默症是和記憶相關的,那麼我們看到大腦記憶相關的部位萎縮,會推測它偏疾病,一般老化應該是大腦整體普遍地老化,而非局部退化得更快。我們認為當未來數據夠大了,有機會可透過腦影像判讀,提早發現罹患失智症的徵兆。
坊間有一些AI軟體號稱可以區分阿茲海默症或其他腦部疾病,可實際上它是從資料庫做區分,當就診病人可能是阿茲海默症伴隨憂鬱症,又或者阿茲海默症伴隨高血壓,甚至是同時罹患憂鬱症、高血壓、糖尿病的複雜病況,還沒有哪種AI軟體可以精確判讀。
也因此,我們還不能夠光憑著腦影像就區別一般老化或者阿茲海默症的腦,雖然可能可以透過一些相關特徵來推測,如阿茲海默症是和記憶相關的,那麼我們看到大腦記憶相關的部位萎縮,會推測它偏疾病,一般老化應該是大腦整體普遍地老化,而非局部退化得更快。我們認為當未來數據夠大了,有機會可透過腦影像判讀,提早發現罹患失智症的徵兆。
坊間有一些AI軟體號稱可以區分阿茲海默症或其他腦部疾病,可實際上它是從資料庫做區分,當就診病人可能是阿茲海默症伴隨憂鬱症,又或者阿茲海默症伴隨高血壓,甚至是同時罹患憂鬱症、高血壓、糖尿病的複雜病況,還沒有哪種AI軟體可以精確判讀。
如何運用大數據
「醫生常常問我們一個問題,從病人確診的這個時間點開始,我們有沒有辦法幫助醫生,預測病人未來的病況,有沒有辦法給予建議或者方式,幫助病人不要往那個方向走,或是延緩;甚至有沒有可能在確診之前的更早幾年就看到這個趨勢。」林慶波教授說道:「這是我終極的目標啦!」
現在不同醫院所採的影像不一樣,以MRI來講,同一個人的腦用不同的參數取得的腦影像,結果就不一樣,這就是最主要的大問題,所有醫院都有MRI的數據,大家以為大數據放在一起就可以,這想法是錯的,不同的醫院參數不同就不可能放在一起用,簡單說就是沒有標準化。可是訂立標準化會牽涉到廠商的利益和專利,再加上拉長掃描時間,醫院也不太願意配合。
「醫生常常問我們一個問題,從病人確診的這個時間點開始,我們有沒有辦法幫助醫生,預測病人未來的病況,有沒有辦法給予建議或者方式,幫助病人不要往那個方向走,或是延緩;甚至有沒有可能在確診之前的更早幾年就看到這個趨勢。」林慶波教授說道:「這是我終極的目標啦!」
現在不同醫院所採的影像不一樣,以MRI來講,同一個人的腦用不同的參數取得的腦影像,結果就不一樣,這就是最主要的大問題,所有醫院都有MRI的數據,大家以為大數據放在一起就可以,這想法是錯的,不同的醫院參數不同就不可能放在一起用,簡單說就是沒有標準化。可是訂立標準化會牽涉到廠商的利益和專利,再加上拉長掃描時間,醫院也不太願意配合。
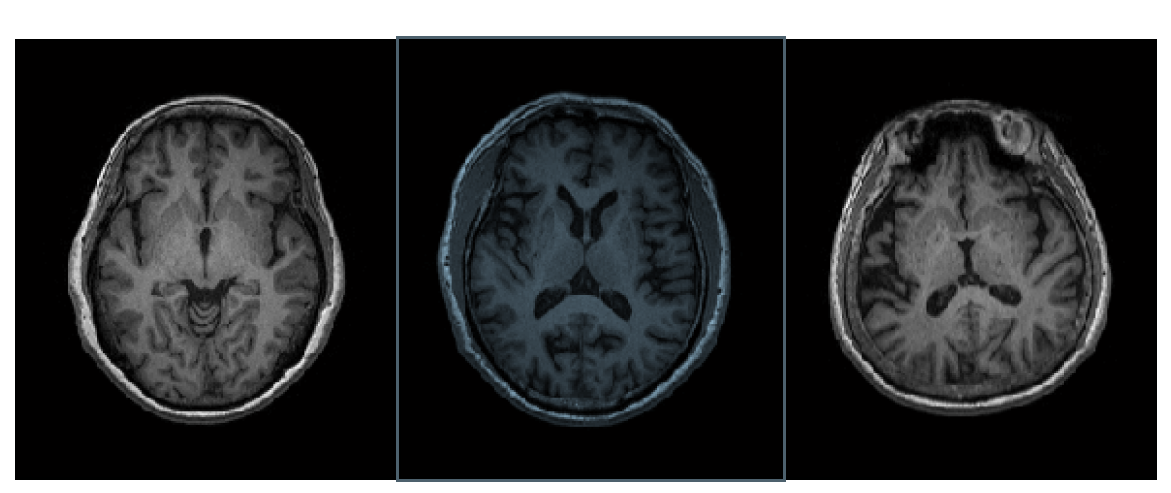
圖:未經標準化步驟的大腦MRI影像
|
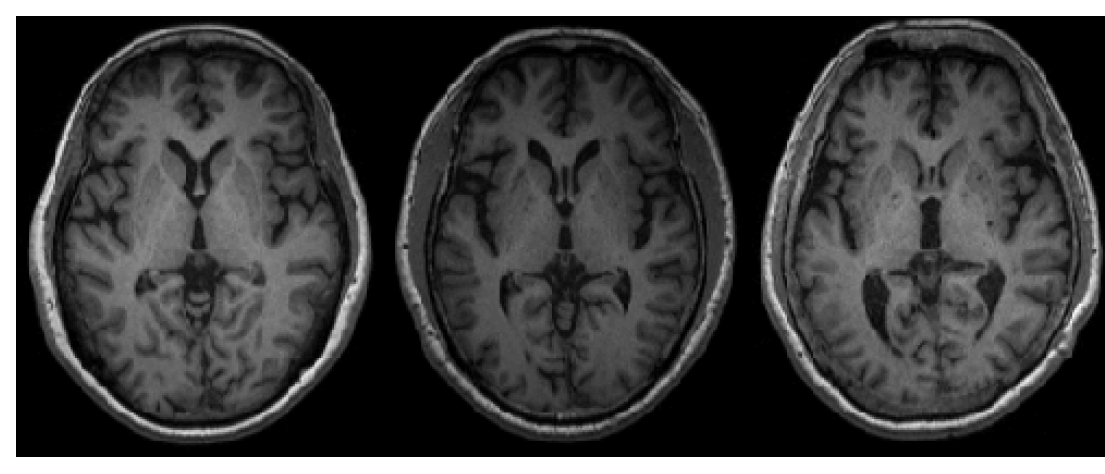
圖:經標準化步驟的大腦MRI影像
|
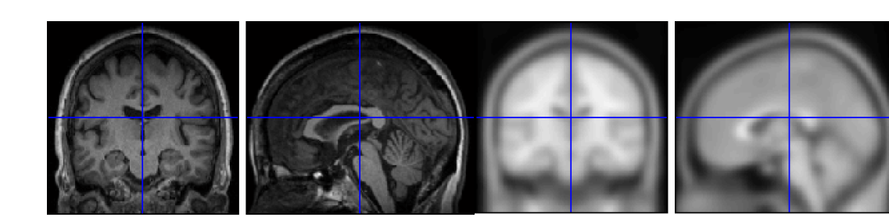
圖:經標準化步驟的大腦影像與模板關係
為了解決掃描影像本身無法標準化的問題,我們只能從後端AI來改善,這也是目前嘗試的方向,但是否能成功,還是個問號。
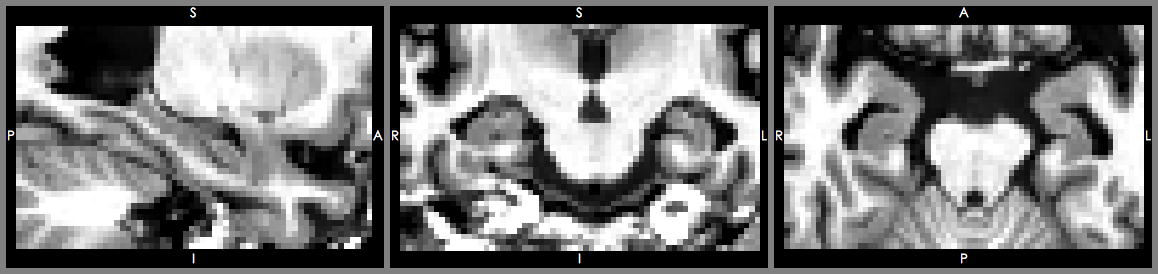
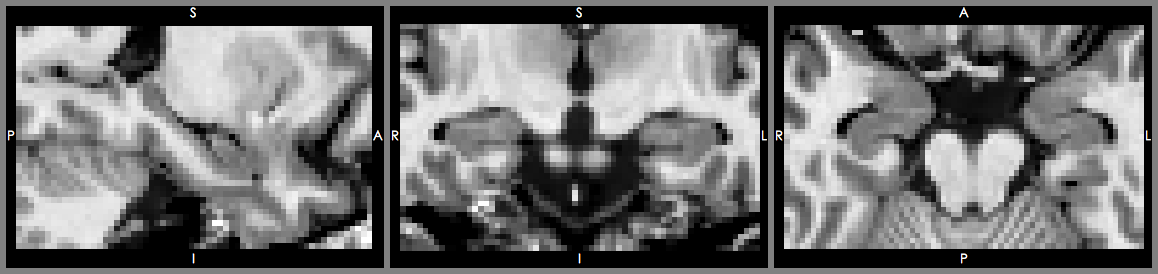
圖: (上) 61歲女性阿茲海默症患者海馬迴,(下)61歲女性正常人海馬迴
|
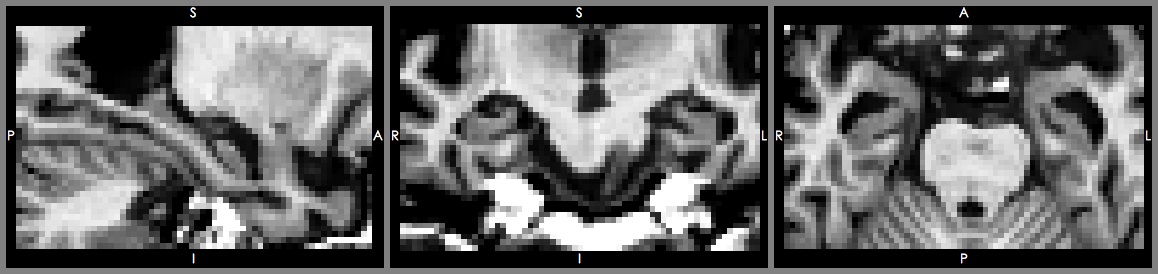
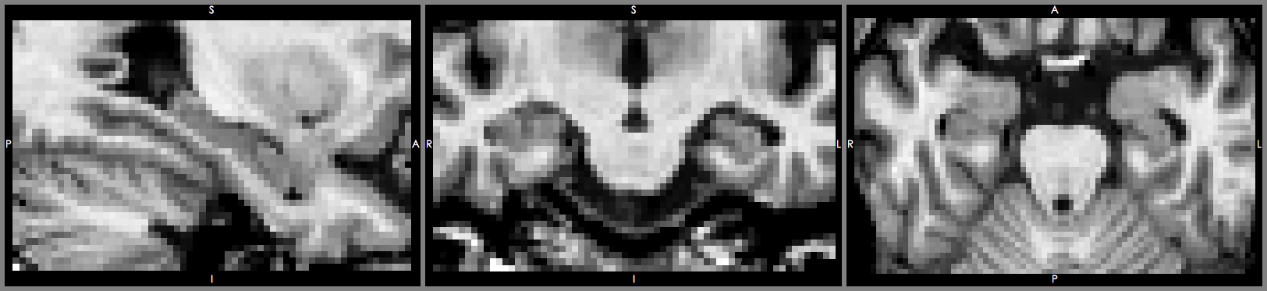
圖: (上) 86歲女性阿茲海默症患者海馬迴、(下)86歲女性正常人海馬迴
|
玩數據的人總是會希望數據庫大,但從我們的角度來講,本質比數據大更重要,如果數據的本質是亂的,譬如我們常講的例子,同一個精神病患給十個精神科醫生檢驗,可能得到十個不同的診斷,這不見得是醫生的錯,也有一些是病人現在就是沒有一個顯著的標記,今天在你面前表現是什麼樣子,醫生也只能看到當下的表現,他就算花了很多時間談了幾個小時,也只能從當下的表現診斷,這就不是在一個一定的基準上。再加上影像本身沒有統一的方法、參數不一樣,各自的誤差就在污染。在統計學上,數據量大的目的只是為了排除汙染,可是有些數據污染的太嚴重的時候,再大也沒有用。
AI統計的是生活中很多非線性的改變量,大家一直在講大數據,大數據的目的只是為了降低這些干擾項。有人覺得數據夠大就可以操作,可是其實從某個角度來講,那還不如好好的收集數據,而且MRI腦影像也不可能收到上萬筆、上十萬張,自然張張重要、張張精彩。因此我們自己建了一個一千多筆的數據庫,從單一位阿茲海默症的病人或是行為認知障礙的病人的腦影像來追蹤比對,看他整個腦體積的改變,確實就可以看到差異。所以,運用AI還是要有資料庫,只是這個資料庫大或小,有了資料庫,自然就可以去做一點點事情。
AI統計的是生活中很多非線性的改變量,大家一直在講大數據,大數據的目的只是為了降低這些干擾項。有人覺得數據夠大就可以操作,可是其實從某個角度來講,那還不如好好的收集數據,而且MRI腦影像也不可能收到上萬筆、上十萬張,自然張張重要、張張精彩。因此我們自己建了一個一千多筆的數據庫,從單一位阿茲海默症的病人或是行為認知障礙的病人的腦影像來追蹤比對,看他整個腦體積的改變,確實就可以看到差異。所以,運用AI還是要有資料庫,只是這個資料庫大或小,有了資料庫,自然就可以去做一點點事情。
